
It’s not very well known that the Raspberry Pi has a built-in serial console that provides a fully working Linux terminal over serial. This allows for network-free headless access, including the absolutely necessary tab auto-complete! This feature is extremely useful for those projects that don’t use a screen or need network access. It’s also quite necessary when you are using a Pi as a wireless access point for a LAN without internet sharing.
Quick disclaimer: This article assumes basic familiarity with the Raspberry Pi and the basics of interfacing with serial devices. I’m using Windows to demonstrate but this works equally well on Linux and Mac.
Hardware
You’ll need a Raspberry Pi (of course) and a USB -to-Serial device (like this one from Adafruit).
Firstly, connect the RX of the USB-to-Serial device to Pin 8 of the Pi (physical Pin 8, not the GPIO pin number) and TX of the USB-to-Serial device to Pin 10 of the Pi.
Remember, for UART communication you do not match up TX <–> TX and RX <–> RX, it’s the opposite (TX –> RX and RX <– TX) since one device transmits and the other receives.

Finally, connect the ground of the USB-to-Serial device to Pin 6 of the Pi (ground).
NOTE: Do NOT connect the 5V power wire from the USB-to-Serial adapter to the 5V power pin of the Pi. This can backpower the Pi and destroy it. All that’s necessary is that the USB-to-Serial adapter and Pi share the same ground reference. Using the Adafruit adapter, the connections look like the picture at the top of the page.
Software
To enable the serial console just add the line:
enable_uart=1
to /boot/config.txt on the Pi. /boot/ is also mounted automatically on Windows so you can do this on a fresh image immediately after burning to the SD card (you may need to take it out and re-insert it first).
After connecting the USB-to-Serial adapter you can figure out the serial COM port using device manager.
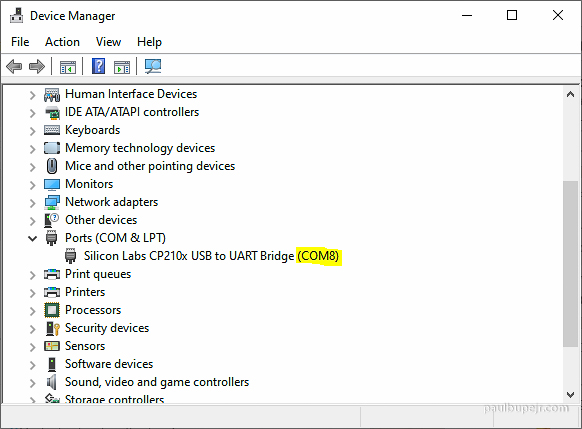
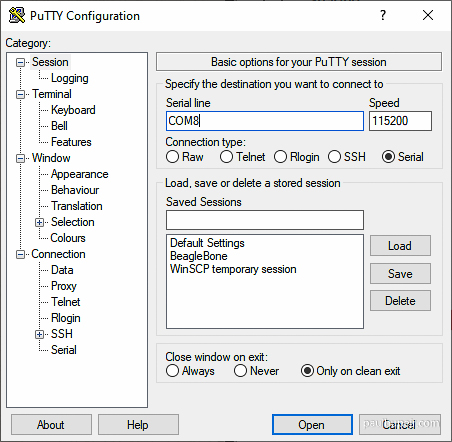
The serial port needs to be configured with the settings below. Generally everything below but the baud rate are the default on most systems so that’s all you need to specify.
Speed (baud rate): 115200
Bits: 8
Parity: None
Stop Bits: 1
Flow Control: NoneIn this case I’m using PuTTY to connect to the Pi as shown:
After connecting you should be met with a blank screen, simply press ENTER to send a character and you’ll see the familiar login prompt. Enter the login credentials and you’re in, just like you SSH’d in!

To demonstrate that this is a fully working terminal you can even launch the “graphical” raspi-config utility.

That’s it!
This should hopefully be a useful bit of info for the more advanced projects that don’t use the Pi with a screen and mouse/keyboard connected.
One thought on “Raspberry Pi Headless Access Using Built-in Serial Console”